
📒 Vue diff 算法
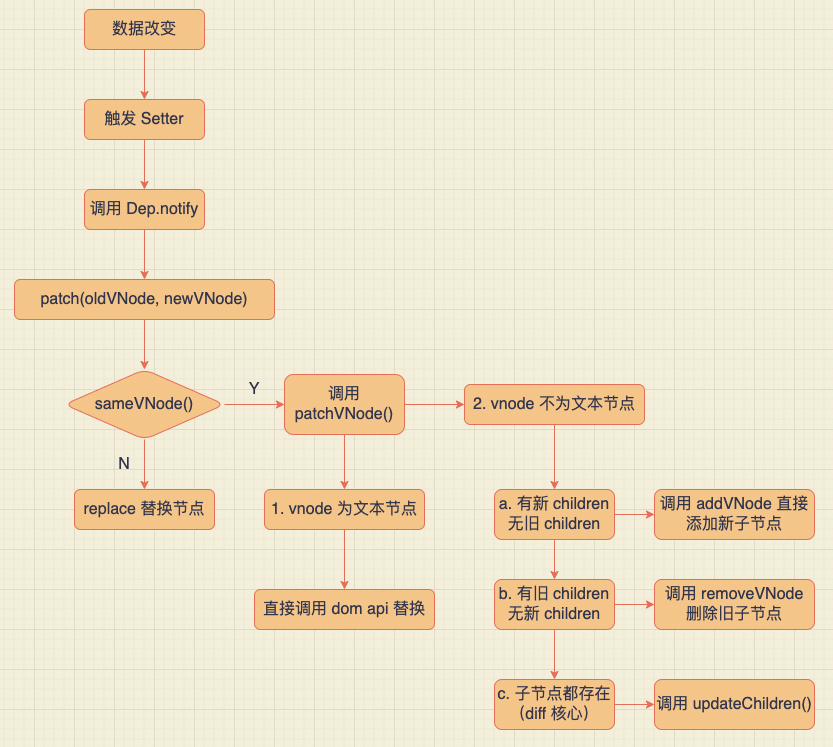
Vue2 diff 算法核心流程如下:
- diff 的入口函数为
patch,使用sameVnode比较节点是否相同,如相同则使用patchVnode继续进行深层比较,否则就使用createEle方法渲染出真实 DOM 节点,然后替换旧元素节点 sameVnode通过比较key值是否一样、标签名是否一样、是否都为注释节点、是否都定义data、当标签为input时,type是否相同来判断两个节点是否相同patchVnode方法如何对节点深层比较- 拿到真实 DOM 的节点
el(即oldVnode.el) - 判断当前
newVnode和oldVnode是否指向同一对象,如果是直接return - 如果新旧虚拟节点是文本节点,且文本不一样,则直接将真实 DOM 中文本更新为新虚拟节点的文本;若文本没有变化,则继续对比新旧节点的
children - 如果
oldVnode有子节点而newVnode没有,则删除el的子节点 - 如果
oldVnode没有子节点而newVnode有,则将newVnode的子节点渲染出真实 DOM 添加到el(Vue 源码中会判断是否有key重复) - 如果两者都有子节点,则执行
updateChildren函数比较子节点
- 拿到真实 DOM 的节点
updateChildren是 diff 算法核心部分,当发现新旧虚拟节点的子节点都存在时,需要判断哪些节点是需要移动的,哪些节点是可以直接复用的,进而提高 diff 的效率- 通过 首尾指针法,在新旧子节点的首位定义四个指针,然后不断对比找到可复用的节点,同时判断需要移动的节点
- 非理想状态下只能通过节点映射的方式去找可复用节点,时间复杂度为
O(n^2) - Vue3 的 diff 算法在非理想状态下的节点对比使用了最长递增子序列来处理,时间复杂度为
O(nlgn)~O(n^2)
📒 Leetcode 300 最长递增子序列
常规方式是使用动态规划,时间复杂度 O(n^2)。这里注意 dp[i] 的定义是 以 nums[i] 这个数结尾的最长递增子序列长度。
class Solution {
public int lengthOfLIS(int[] nums) {
// 定义 dp 数组
// dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列长度
int[] dp = new int[nums.length];
// 初始值填充 1(子序列至少包含当前元素自己)
Arrays.fill(dp, 1);
for (int i = 0; i < nums.length; i++) {
for (int j = 0; j < i; j++) {
// 假设 dp[0...i-1] 都已知,需要求出 dp[i]
// 只需要遍历 nums[0...i-1],找到结尾比 nums[i] 小的子序列长度 dp[j]
// 然后把 nums[i] 接到最后,就可以形成一个新的递增子序列,长度为 dp[j] + 1
// 显然,可能形成很多种新的子序列,只需要选择最长的,作为 dp[i] 的值即可
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
}
// 遍历 dp 数组,找出最大值
int res = 0;
for (int i = 0; i < dp.length; i++) {
res = Math.max(res, dp[i]);
}
return res;
}
}
📒 CSS 中的 object-fit 属性用法
在项目中有一个需求,图片尺寸较小时,需要保存图片原有大小,图片尺寸大于容器大小时,需要缩放以适合容器大小,同时保持原有比例。
查阅 MDN 文档可知,在 <img> 和 <video> 等替换元素上可以使用 object-fit 属性,用于设置替换元素该如何适配容器,可以取以下几个值:
object-fit: fill:图片被拉伸以适应容器,这种方式不会保持长宽比object-fit: contain:图片被缩放以适应容器,同时保持长宽比,如果图片与容器长宽比不匹配,较短边会留出空白object-fit: cover:图片被缩放以适应容器,同时保持长宽比,如果图片与容器长宽比不匹配,较长边会被剪裁object-fit: none:图片不会调整大小object-fit: scale-down:图片较小时使用none,图片较大时使用contain
综上,使用 object-fit: scale-down 就可以实现项目需求。
注意 IE 11 不支持
object-fit
📒 理解归并排序
归并排序就是对数组的左半边和右半边分别排序,然后再合并两个有序数组。
- 归并排序的过程可以在逻辑上抽象成一棵二叉树,树上的每个节点的值可以认为是
nums[lo..hi],叶子节点的值就是数组中的单个元素 - 然后,在每个节点的后序位置(左右子节点已经被排好序)的时候执行
merge函数,合并两个子节点上的子数组 - 这个
merge操作会在二叉树的每个节点上都执行一遍,执行顺序是二叉树后序遍历的顺序
一句话总结,归并排序实际上就是先对数组不断进行二分,分到只有一个元素为止,此时
merge方法开始发挥作用,将两个元素为一组,合并为长度为 2 的有序数组,再将两个长度为 2 的有序数组为一组,合并为长度为 4 的有序数组,以此类推
class Merge {
// 用于辅助合并有序数组(不能原地合并,需要借助额外空间)
private static int[] temp;
public static void sort(int[] nums) {
// 避免递归中频繁分配和释放内存可能产生的性能问题
// 提前给辅助数组开辟内存空间
temp = new int[nums.length];
// 原地修改的方式对整个数组进行排序
sort(nums, 0, nums.length - 1);
}
// 定义:将子数组 nums[lo..hi] 进行排序
private static void sort(int[] nums, int lo, int hi) {
if (lo == hi) {
// 单个元素不用排序
return;
}
// 这样写是为了防止溢出,效果等同于 (hi + lo) / 2
// 注意:对于无法整除的情况,Java 中 int 类型会自动向下取整
int mid = lo + (hi - lo) / 2;
// 先对左半部分数组 nums[lo..mid] 排序
sort(nums, lo, mid);
// 再对右半部分数组 nums[mid+1..hi] 排序
sort(nums, mid + 1, hi);
// 将两部分有序数组合并成一个有序数组
merge(nums, lo, mid, hi);
}
// 将 nums[lo..mid] 和 nums[mid+1..hi] 这两个有序数组合并成一个有序数组
private static void merge(int[] nums, int lo, int mid, int hi) {
// 先把 nums[lo..hi] 复制到辅助数组中
// 以便合并后的结果能够直接存入 nums
for (int i = lo; i <= hi; i++) {
temp[i] = nums[i];
}
// 数组双指针技巧,合并两个有序数组
// i => 左半边数组起始下标
// j => 右半边数组起始下标
int i = lo, j = mid + 1;
for (int p = lo; p <= hi; p++) {
if (i == mid + 1) {
// 左半边数组已全部被合并,只需把右半边数组合并过来即可
nums[p] = temp[j++];
} else if (j == hi + 1) {
// 右半边数组已全部被合并,只需把左半边数组合并过来即可
nums[p] = temp[i++];
} else if (temp[i] > temp[j]) {
// 将较小的元素合入,同时下标前进一位,此时是升序
// 只要将 > 改为 < 就可以把结果改为降序
nums[p] = temp[j++];
} else {
nums[p] = temp[i++];
}
}
}
}
归并排序时间复杂度为
O(nlogn)
🌛 Leetcode 112 路径总和
判断是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root == null) return false;
if (root.left == null && root.right == null) {
return (targetSum - root.val) == 0;
}
boolean leftResult = hasPathSum(root.left, targetSum - root.val);
boolean rightResult = hasPathSum(root.right, targetSum - root.val);
return leftResult || rightResult;
}
}
📒 Podman 已成 Linux 官方标配!Docker 没戏了?
⭐️ 不懂动态规划?21道 LeetCode题目带你学会动态规划!
⭐️ 浅析 Snabbdom 中 vnode 和 diff 算法
📒 HTTP 缓存最佳实践
在配置 nginx 的时候,可以配置合理的缓存策略,例如:
- html 文件配置协商缓存
- js、css、图片、字体等文件由于带有哈希,可以配置一年强缓存
这里的缓存更新逻辑:
当 js、css 等静态资源文件修改后,文件哈希发生变化,对应引入 html 的文件地址也发生变化,等于 html 文件也被修改。因此浏览器端会获取到最新的 html 文件,然后根据带有哈希的路径加载最新的静态资源文件。
这样配置缓存之后,可以极大提升资源二次加载速度,进而提升用户体验。以上这些是从性能角度考虑的,从安全角度考虑,推荐如下配置:
- 为了防止中介缓存,建议设置
Cache-Control: private,这可以禁用掉所有Public Cache(比如代理),这就减少了攻击者跨界访问到公共内存的可能性 - 默认情况下,浏览器使用 URL 和 请求方法 作为缓存 key,这意味着,如果一个网站需要登录,不同用户的请求由于它们的请求URL和方法相同,数据会被缓存到一块内存里。如果我们请求的响应是跟请求的
Cookie相关的,建议设置Vary: Cookie作为二级缓存 key
📒 跨域,不止CORS
通常提到跨域问题的时候,相信大家首先会想到的是 CORS (Cross Origin Resource Sharing),其实 CORS 只是众多跨域访问场景中安全策略的一种,类似的策略还有:
COEP (Cross Origin Embedder Policy):跨源嵌入程序策略COOP (Cross Origin Opener Policy):跨源开放者政策CORP (Cross Origin Resource Policy):跨源资源策略CORB (Cross Origin Read Blocking):跨源读取阻止
为何有时候服务端没有给响应头设置 Content-Type,浏览器还能正确识别资源类型
当服务端没有设置 Content-Type 或者浏览器认为类型不正确时,浏览器会读取资源的字节流,进行 MIME 类型嗅探。这就可能导致一些敏感数据被提交到内存,攻击者随后可以利用 Spectre 之类的漏洞来潜在地读取该内存块。
https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types#mime_sniffing
为了使我们的网站更加安全,建议所有网站都开启 CORB,只需要下面的操作:
- 配置正确的
Content-Type(例如,HTML 资源设置text/html) - 开启
X-Content-Type-Options: nosniff来禁止客户端进行自动 MIME 嗅探
新的跨域策略:使用COOP、COEP为浏览器创建更安全的环境
📒 如何监听系统黑暗模式
在 CSS 中可以通过 prefers-color-scheme 媒体查询实现:
body {
color: black;
background: white;
}
@media (prefers-color-scheme: dark) {
body {
color: white;
background: black;
}
}
在 JS 中可以使用 window.matchMedia 媒体查询:
import React from "react";
export type ThemeName = "light" | "dark";
function useTheme() {
const [themeName, setThemeName] = React.useState<ThemeName>("light");
React.useEffect(() => {
// 设置初始皮肤
if (window.matchMedia("(prefers-color-scheme: dark)").matches) {
setThemeName("dark");
} else {
setThemeName("light");
}
// 监听系统颜色切换
window
.matchMedia("(prefers-color-scheme: dark)")
.addEventListener("change", (event) => {
if (event.matches) {
setThemeName("dark");
} else {
setThemeName("light");
}
});
}, []);
return {
themeName,
isDarkMode: themeName === "dark",
isLightMode: themeName === "light",
}
}
https://developer.mozilla.org/zh-CN/docs/Web/API/Window/matchMedia
自定义 hook 实际上就是 mixin,把一段可复用的逻辑抽离出来
📒 搜索 JS、Go、Java、Python 的第三方库
例如搜索 Redux 的替代方案:
https://openbase.com/js/redux/alternatives
📒 深入理解 React Native 的新架构
照 React Native 团队去年发表的一篇 博客 的说法,他们会在今年发布新的架构。本文将会详细介绍新架构的相关内容。
https://medium.com/coox-tech/deep-dive-into-react-natives-new-architecture-fb67ae615ccd
📒 QUIC——快速UDP网络连接协议
- QUIC 的Stream流基于Stream ID+Offset进行包确认,流量控制需要保证所发送的所有包offset小于 最大绝对字节偏移量 ( maximum absolute byte offset ), 该值是基于当前 已经提交的字节偏移量(offset of data consumed) 而进行确定的,QUIC会把连续的已确认的offset数据向上层应用提交。QUIC支持乱序确认,但本身也是按序(offset顺序)发送数据包
- QUIC利用ack frame来进行数据包的确认,来保证可靠传输。一个ack frame只包含多个确认信息,没有正文
- 如果数据包N超时,发送端将超时数据包N重新设置编号M(即下一个顺序的数据包编号) 后发送给接收端
- 在一个数据包发生超时后,其余的已经发送的数据包依旧可以基于Offset得到确认,避免了TCP利用SACK才能解决的重传问题
其实QUIC的乱序确认设计思想并不新鲜,大量网络视频流就是通过类似的基于UDP的RUDP、RTP、UDT等协议来实现快速可靠传输的。他们同样支持乱序确认,所以就会导致这样的观看体验:明明进度条显示还有一段缓存,但是画面就是卡着不动了,如果跳过的话视频又能够播放了