封面图:Safe by construction - Roberto Clapis
🌟 AI 相关
- Reflection as a Service 🪞
- 昨天上海 AI lab 开源了一个非常强的多模态 LLM InternLM-XComposer-2.5
- 从 Prompt Engineering 到 Flow Engineering🔥 @CodiumAI 开源了一个 PR-Agent,目前 4.8K Star 🌟,自动基于你提交的代码进行分析,给于评论反馈与意见,生成 PR 描述!
- Nice overview kind of Paper - "Searching for Best Practices in Retrieval-Augmented Generation"
- 麻省理工这本《深入理解深度学习》的免费书可太好了。深入讲解了深度学习的大部分概念。而且每个章节都有搭配的PPT可以下载,还有对应练习的Python代码。内容包括监督学习、神经网络、损失函数、正则化、卷积网络、Transformers、扩散模型、强化学习等。
- 🏆如何实现财务自由的21条准则:顶级商学院课件 深入浅出 初学专业兼具底层思维分享
- 非常值得一看的视频,OpenAI 联合创始人 Andrej Karpathy 在2024年加州大学伯克利分校人工智能黑客马拉松颁奖典礼上的主题演讲
- 大模型产品化第一年:战术、运营与战略
- What We Learned from a Year of Building with LLMs (Part I)
- 支持 10+ 翻译器的漫画或图片翻译神器 - Image/Manga Translator 开源!🔥目前 4 6K Star
- Reddit 上的这个 lectures 频道,包含很多值得一听的视频讲座、演讲和有趣的公开演讲,包括数学、物理、计算机科学、编程、工程、生物、医学、经济学、政治、社会科学这类学科的知识
- 转译:《如何使用ChatGPT撰写科学研究论文?- Dr Asma Jabeen》
- 刚才翻 MySQL 文档,切文档版本的时候,发现 MySQL 9.0 发布了
- GraphRAG, a graph-based approach to retrieval-augmented generation (RAG) that significantly improves question-answering over private or previously unseen datasets, is now available on GitHub
- GraphRAG: New tool for complex data discovery now on GitHub
- 下一代 RAG 技术来了!微软正式开源 GraphRAG🔥 通过 LLM 构建知识图谱结合图机器学习,极大增强 LLM 在处理私有数据时的性能,同时 GraphRAG 具备连点成线的跨大型数据集的复杂语义问题推理能力
- How to Fine-tune a Large Language Model
- Gemma 2: Improving Open Language Models at a Practical Size
- ncnn Vulkan 机器学习最新进展
- The Future of Knowledge Assistants 🤖
- Cool repo from @huggingface - local-gemma: Gemma 2 optimized for your local machine 🔥
- Claude 3.5 的 Artifacts 确实非常惊艳,在跟他讨论问题时,他不但耐心地给你仔细分析优缺点,还随手抓过一张纸开始画流程图,边画边说。。。
- RAG 最佳实践探索
- A recent Q* Paper - On MATH, surpasses GPT-4 and Gemini Ultra. 🔥
- 假如你想看 AI 相关的最新消息,可以关注这个推特 AI 列表 「AI Leaders」,时效性会快于国内翻译搬运的好几天,甚至可以置顶到列表项方便阅读
- 一个基于LangChain 实现RAG(检索增强型生成)的指南!
- 60 AI Tools to Start Your Profitable Online Business in 2024
- Mooncake 是 Moonshot AI 提供的领先的 LLM 服务 Kimi 的服务平台,目前已经在知乎发表 3 偏技术报告:
- Mooncake 技术报告中提出 3 个论点:
- 存算分离的 KVCache 策略是长期趋势(立马就可以省钱
- 与 MLA、KVCache 压缩方案正交,KVCache 变小意味着 Mooncake 方案收益明显
- 为芯片设计提供参考,未来 2~3 年可能会是趋势
- 中文解读版本:月之暗面kimi底层推理系统方案揭秘
- 为 RAG 场景微调嵌入模型
- Fantastic paper for Reward Model Training in RLHF ✨
- Multi-agents on k8s 🤖
- 置身事内 - 中国政府与经济发展
- Brilliant new paper, HUGE for LLM's internalized knowledge 🔥
- A very intriguing recent paper "Nested Jailbreak Prompts can Fool LLMs Easily" - reveals the inadequacy of current defense methods in safeguarding LLMs.
- 专为 LLM 打造的智能缓存技术 - GPTCache 开源并发布论文,目前 6.7K Star 🌟
- 用 DALL-E 给文章配图我是这么用的
- 支持爬取网页、解析音视频/PDF 等 10+ 格式文件🔥,LlamaIndex LlamaParse 开源平替,超强的 AI 数据源解析器 - OmniParse 开源,目前 457 Star 🌟!
- 原来微软的这套《Generative AI for Beginners》还有中文版。内容不深,作为入门教程快速通读一遍还是可以的
- 💻 Gemini 推出代码解析器:Code execution
- This 76-page paper on Prompting Techniques has become quite popular. A nice read for your weekend
2024年6月后2周重要的大语言模型论文总结:LLM进展、微调、推理和对齐
RouteLLM:高效LLM路由框架,可以动态选择优化成本与响应质量的平衡
RAGFlow开源Star量破万,是时候思考下RAG的未来是什么了
社区供稿 | 加速基于 Arm Neoverse N2 的大语言模型推理
LLaMA Factory:从预训练到RLHF,大模型高效训练框架
图解大模型计算加速系列:分离式推理架构1,从DistServe谈起
GPT-4预测股票涨跌更更更准了!东京大学新框架LLMFactor提升显著 | ACL 2024
使用‘消除’技术绕过LLM的安全机制,不用训练就可以创建自己的nsfw模型
SOFTS: 时间序列预测的最新模型以及Python使用示例
Claude 3.5 Sonnet 超越 GPT-4o成为最智能的模型,新功能artifacts可以实时查看和迭代生成的代码
Llama也能做图像生成!港大字节推出开源自回归文生图模型,在线体验已开放
240万亿巨量数据被洗出,足够训出18个GPT-4!全球23所机构联手,清洗秘籍公开
ICML 2024 Spotlight | 在解码中重新对齐,让语言模型更少幻觉、更符合人类偏好
Web2Code:一款用于网页转代码的全套数据集(含训练数据和评估框架),得分显著提升
AIOps的工业化应用:有 42%的机会让Meta在发现故障后几分钟内就定位到潜在的根本原因
大模型国产化适配10-快速迁移大模型到昇腾910B保姆级教程(Pytorch版)
ICML 2024 | 无需LayerNorm简化Attention,精度无损推理效率大幅提升
拆分Transformer注意力,韩国团队让大模型解码提速20倍
模型实操 | 从零开始,用英伟达T4、A10训练小型文生视频模型
BigCodeBench: 继 HumanEval 之后的新一代代码生成测试基准
打败GPT4!仅用1/24成本的混合智能体架构逆袭 (mixture of agents)
llama-index团队开源面向生产级多智能体系统的开源框架:llama-agent
从零开始,用英伟达T4、A10训练小型文生视频模型,几小时搞定
ICML2024 & 北大|探究Transformer如何进行推理?基于样例还是基于规则
kimi chat大模型的200万长度无损上下文可能是如何做到的
⭐️ Go & 云原生 & Rust 相关
- sans-IO 高性能网络服务实现:Firezone公司用Rust实现了他们网络服务中的一个关键组件,并总结了一套关于高性能安全开发网络服务的心得。并实现在了 sans-IO 中
- 使用 WASM 和 Rust 从零实现 React v18:这是一个系列文章的第 16 部分,介绍如何从零开始使用 WASM 和 Rust 实现 React v18 的核心功能
- htmd: HTML to Markdown for Rust
- ezpkg.io - Collection of packages to make writing Go code easier
- How to Implement Two-Factor #Authentication (2FA) in #Golang
从 Docker Hub 拉取镜像受阻?这些解决方案帮你轻松应对
🌟 从零开始:使用 pyo3-arrow 打造高效的 Python-Rust 数据桥梁
Go语言助力安全测试:24小时内发送5亿次HTTP/1.1请求
使用 Go 提供的 Cookie 库简化 Cookie 操作
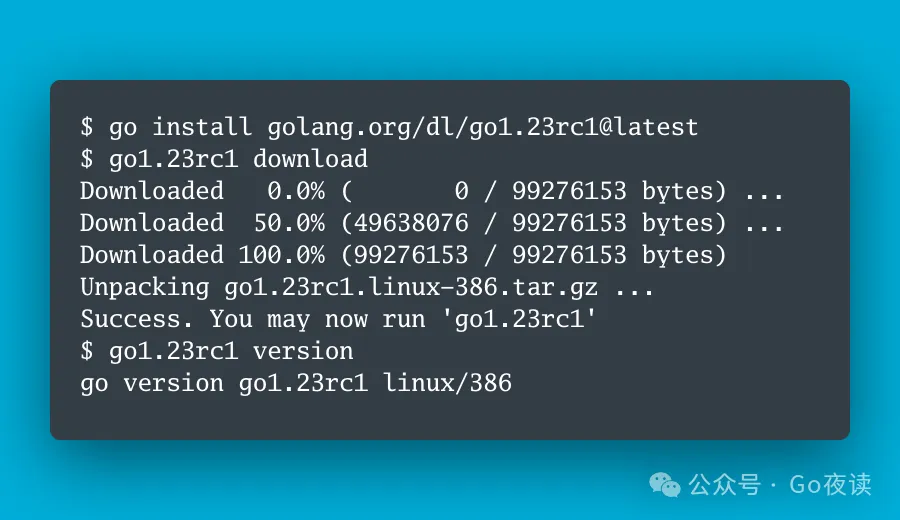
[Go Official]Go 1.22 升级后的更加鲁棒的切片操作
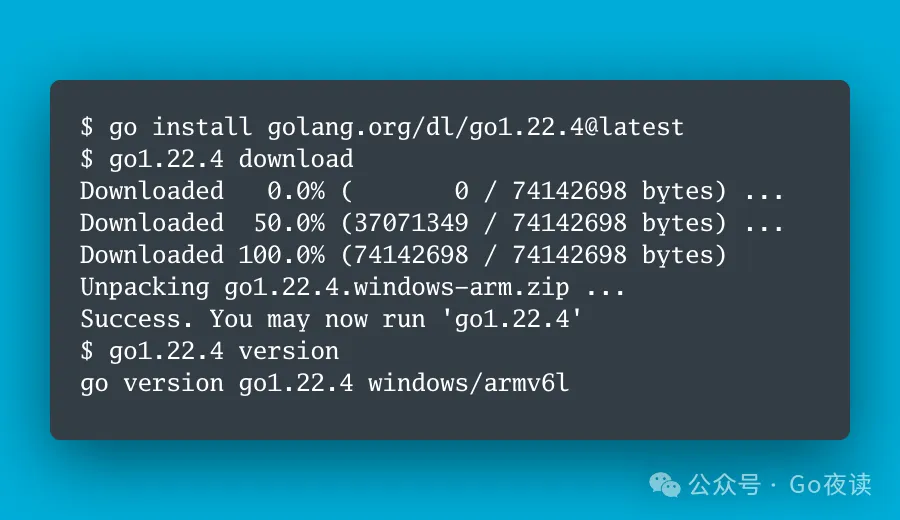
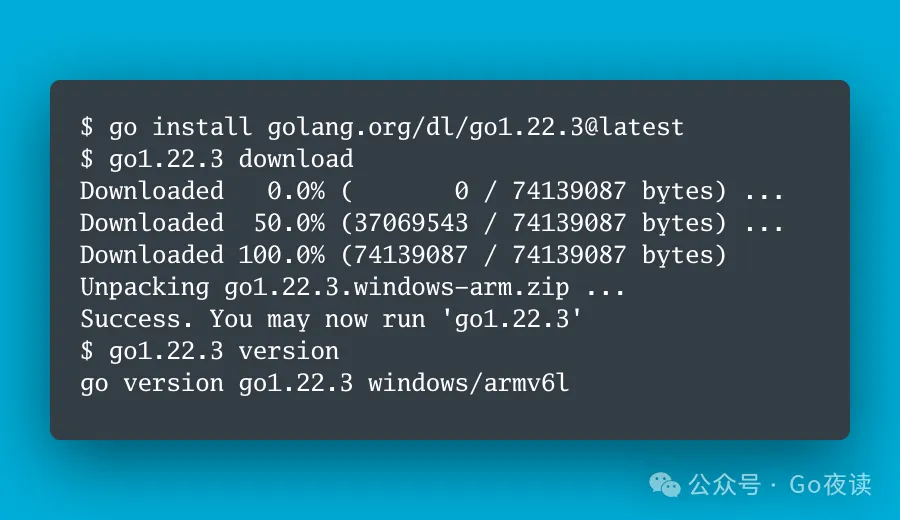
Go 1.22.5 修复 net/http 包中由于不正确的 100-continue 处理而拒绝服务的安全问题
Docker镜像拉取最优解!养一只小猫,利用crproxy高速无感镜像拉取
qsv:Rust实现一个处理CSV文件的简单,快速和可组合的命令行工具
📒 后端相关
秒杀圣经:10Wqps高并发秒杀,16大架构杀招,帮你秒变架构师
Spring Cloud + Nacos + 负载均衡器实现全链路灰度发布实战
熔断、隔离、重试、降级、超时、限流,一文帮你顺理高可用架构流量治理
🌟 订单支付超时如何处理?盘点延迟任务的11种实现方式,你知道几种
📒 前端相关
React 19 新 hook —— useActionState 与 Next.js Server Actions 绝佳搭配
Chrome 127 内置 AI Gemini 大模型,JS 可直接调用!