封面图:Safe by construction - Roberto Clapis
🌟 AI 相关
《首个AI软件工程师Devin完整技术报告出炉,还有人用GPT做出了「复刻版」》。该文章介绍了机器之心报道的 Cognition AI 团队发布的首个 AI 软件工程师 Devin。Devin 在不需要人类辅助的情况下,在 SWE-bench 基础测试中解决了 13.86% 的问题,远高于目前 SOTA 模型的解决率。SWE-bench 是一个复杂的软件工程系统自动化基准测试,用以测试系统解决现实世界代码库中问题的能力。文章还展示了 Devin 在多步规划和定性案例分析中的表现,并说明了其运行方式和评估标准。同时,报告了社区已经产生了复刻版的 Devin,展示了 AI 在软件工程领域的先进能力和潜在的行业变革。
《大模型基础应用框架(ReACT\SFT\RAG)技术创新及零售业务落地应用》。本篇文章由九数算法中台分享,探讨了在零售行业中融入大模型技术应用框架——ReACT、SFT(指令微调)、RAG(检索增强生成)的创新与实际应用。文章提出了这些大模型技术在解决特定领域知识不足、减少内容幻觉、确保数据安全等方面的挑战,并详述了如何通过有监督微调来提升大模型在零售领域的专业知识水平。同时,介绍了京东在多个业务试点应用自研的SFT框架和RAG技术,突显了大模型在零售业务中从理论到实践的转换,以及在多种复杂使用场景中的潜在价值。
《南洋理工发布多模态金融交易Agent,平均利润提高36%!》。本文介绍了南洋理工大学发布的多模态金融交易Agent,通过融合大语言模型(LLMs)和多模态数据处理,提高了金融交易的效益。传统基于规则的交易系统在适应市场波动方面存在不足,而基于强化学习的系统虽然适应性更好,但在处理多模态数据和可解释性方面仍面临挑战。该文中提出的FinAgent是一种先进的多模态基础代理,能够综合分析多种形式的金融数据,提供精确的市场趋势分析和决策支持。实验证明,使用FinAgent进行金融交易可以平均提高36%的利润。论文链接:https://arxiv.org/pdf/2402.18485.pdf
《大模型推理:A100/H100 太贵,何不用 4090?》。本文介绍了大模型推理时,为什么可以考虑使用4090显卡。相比于A100和H100显卡,4090在性价比上更高,尤其在极致优化的情况下,甚至可以达到H100的2倍性能。文章指出,A100、H100和4090在算力方面的差距并不大,最大的区别在通信和内存方面。由于大模型训练使用高性能的通信,4090通信效率相对较低,因此在大模型训练中并不适用。然而,在推理(inference/serving)方面,4090在性价比上有优势,尤其是相对于H100显卡而言。文章还提到了GPU的训练性能和成本对比,以及大模型训练所需的算力和GPU数量等问题。详细内容可参考文章链接。
《精度提升!南加大等 | 提出分治Prompt策略,提升LLM分辨力》。本文介绍了一种基于分治算法的Prompt策略,旨在提高大语言模型(LLM)的分辨力。现有的提示策略在处理涉及重复子任务和含有欺骗性内容的任务时存在一定限制。为了解决这个问题,研究人员提出了一种基于分治算法的提示策略,利用分治程序来引导LLM的求解过程。该策略将任务划分为子问题并分别求解,然后合并子问题的答案。通过实验证明,这种分治策略能够提升模型在大整数乘法、幻觉检测和新闻验证等任务中的性能,相比传统提示策略具有更好的准确率和性能指标。论文地址:https://arxiv.org/pdf/2402.05359.pdf
《开源版“Devin”AI程序员炸场:自己分析股票、做报表、建模型》。这篇文章介绍了一个基于MetaGPT的开源项目Data Interpreter,该项目旨在处理数据实时变化、任务之间的复杂依赖关系、流程优化需求以及执行结果反馈的逻辑一致性等挑战。通过演示,展示了Data Interpreter在分析股票、预测葡萄酒质量、自动抠图、预测疾病进展和预测机器运行状态等方面的能力。该项目由MetaGPT团队与多所高校合作推出,提供了一种自主进行数据分析和建模的开源工具。
《【原创】一文读懂RAG的来源、发展和前沿》。本文介绍了检索增强生成(RAG)技术,该技术结合了检索和生成过程,旨在提高机器生成文本的相关性、准确性和多样性。文章详细解释了幻觉问题的存在以及解决幻觉问题的几种常见方法。RAG利用外部数据源进行信息检索,将检索到的信息作为上下文输入到生成模型中,从而帮助生成正确的响应。讨论了RAG的核心部件,如向量数据库、查询检索和重新排序。同时介绍了RAG在知识图谱和树结构方面的拓展。
《万字长文解析:大模型需要怎样的硬件算力》。这篇文章探讨了大模型在算力、存储、通信等多个方面上硬件资源的挑战和瓶颈。文章分析了以Transformer结构为核心的大模型在算力瓶颈、显存瓶颈和通信瓶颈方面的困境,以及当前所采取的硬件资源优化技术。此外,文章还提供了对大模型参数量和算力需求的量化估算,为选择合适的硬件设备和评估资源需求提供了指导。
《什么是好的大模型训练数据?》。本文基于Lilian Weng的博客,讨论了大模型如LLM在训练过程中对高质量数据的需求。认为高质量数据来源于“高质量人类”产生的标注数据,并强调了数据处理的重要性,提到了数据标注、质量控制和错误修正的重要步骤。文章还讨论了用于评估数据质量的多种方法,如Influence Functions和Noisy Cross-Validation,并提出了专注于“搭建高质量的数据标注pipeline”的企业方向。最后指出,在AI时代大量产出的数据中维护数据质量,是一个值得关注的挑战。
《读过的最白话讲清楚RAG原理的文章》。这篇文章直观地阐释了检索增强生成(RAG)的概念和工作原理,它是一种结合检索和生成的问答系统。该系统首先通过检索步骤找到与用户问题最相关的知识库内容,然后将这些内容与问题共同输入大型语言模型(例如ChatGPT)以生成答案。文章详细介绍了如何利用嵌入模型对知识库文本进行索引,以便协助语言模型进行精确的检索。此外,它还探讨了语义搜索背后的核心原则和技术细节点,如何通过嵌入找到与用户输入最匹配的知识,以及如何格式化文档以供语言模型使用,以便获得更高效的回答。
《LLM推理算法简述》。本文介绍了用于提高大型语言模型(LLM)推理性能的关键技术与策略。内容涵盖显存优化方法,如KV Cache减少显存浪费、MQA和GQA减少KV-Cache数量、Page Attention进行显存管理,以及提高推理速度的FlashAttention改进。文章还探讨了算子融合技术,比如FasterTransformer和DeepSpeed Inference的应用,以及调度优化策略如Async Serving和Dynamic Batch,最后介绍了用于处理大模型的分布式并行技术。这些优化手段能显著提高LLM推理过程中的性能与效率。
《数学推理增强!微软 | 提出数据合成框架:KPDDS,微调Mistral-7B性能超34B模型!》。微软的研究团队为提升大型语言模型(Large Language Models, LLMs)在数学推理任务的性能,提出了关键点驱动的数据合成(KPDDS)框架。KPDDS利用真实数据源中的关键点和示例对生成高质量问答对来训练语言模型。研究者基于此框架创建了KPMath数据集,进一步结合推理密集型数据形成KPMath-Plus数据集。在MATH测试集上,微调后的Mistral-7B模型达到了39.3%的零样本通过率,超越了数量更多的34B模型,证明了KPDDS的有效性与创新性。这一成果标志着LLMs在数学推理方面的性能得到显著提升。
《首个AI软件工程师上线!已通过公司面试抢程序员饭碗,华人创始团队手握10块IOI金牌》。在这篇文章中介绍了由华人创立的Cognition AI公司开发出来的首个人工智能软件工程师Devin。与现有GPT-4等模型不同,Devin能够独立完成复杂的编程任务,并已成功通过人工智能公司的面试和在自由职业平台Upwork上接单。得益于Cognition AI在长期推理和规划方面的进步,Devin在做决策和执行任务时,能回想相关上下文、随时间学习并修复错误。这标志着人工智能在理解真实世界软件工程问题方面取得了突破,为AI领域迈向更高层级的自动化及监督性工作开辟道路。
《向数字世界AGI迈进!智能体已经从头开玩「荒野大镖客 2」了》。这篇文章展示了如何使用Cradle这一通用计算机控制智能体框架进行AI的研究与应用,在无需内部API支持下控制键盘和鼠标以及与各类软件交互。文章来源于北京智源人工智能研究院、新加坡南洋理工大学和北京大学的联合研究。Cradle由六大模块组成,包括信息收集、自我反思、任务推断、技能管理、行动计划和记忆模块。这些模块让智能体能够自主进行决策和任务执行。研究团队通过将Cradle部署于《荒野大镖客 2》这一复杂的3A游戏中证明其通用性,Cradle能够自主完成游戏主线和探索开放世界。智能体的这种通用能力标志着智能体研究向通用人工智能(AGI)迈进的重要一步。
《深入浅出 LangChain 与智能 Agent:构建下一代 AI 助手》。文章深入讲解了LangChain工具箱及其如何赋能智能Agent,以构建更加智能的AI助手。LangChain利用大型语言模型如GPT-4,提供了一个开源软件框架,可助力开发者搭建基于语言模型的应用。它提供了六大类组件,如模型、提示模板、索引、文档加载器、文本分割器和向量存储,让GPT-4等模型不仅能处理语言,还能与外部API互动、管理用户上下文。文章以构建人脸技术问题排查助手为例,展示如何运用LangChain来协助问题诊断与智能交互,朝向自主、高效的智能应用发展。
《使用零一万物 200K 模型和 Dify 快速搭建模型应用》。本文详细介绍了如何使用零一万物的200K模型和Dify(LLM IDE)快速构建模型应用程序。作者首先对一个机器学习电子书进行翻译,并分享了源代码,然后引导读者如何申请和配置零一万物模型API。随后,作者说明了如何使用Dify IDE快速搭建和调试模型应用程序,以及如何使用Golang和AI模型自动化电子书的翻译过程。最后,作者总结了自动翻译程序的构建过程并展示了批量翻译内容的方法。整篇文章不仅是使用Dify的实操指南,还提供了一种效率化、自动化处理文本内容的示例,适合那些在寻找快速开发和集成大语言模型到应用中的开发者参考。
《一文看完多模态:从视觉表征到多模态大模型》。本文为读者系统梳理了图文多模态与多模态大模型领域的发展,尤其聚焦在视觉表征和视觉与文本融合方法上。文章从卷积神经网络(CNN)及其预训练方法开始讲起,从图像处理的视角介绍了多模态融合的初期方法,如LXMERT、VL-BERT和UNITER等。进一步,文章论述了Vision Transformer(ViT)及其预训练方案如MAE和BEIT,以及基于ViT的多模态对齐与预训练技术,如CLIP和VILT等。作者通过丰富的示例和对比,使读者能够理解这些模型在结构和功能上的不同与联系,为进一步研究提供了宝贵的资源和视角。
《浙大&中科院让Agent学会自我进化,玩德州扑克心机尽显》。Wenqi Zhang等研究者介绍了名为Agent-Pro的AI智能体,它使用大模型(GPT-4)为基础,配合自我优化的策略,能够运用虚张声势、主动放弃等复杂策略玩转德州扑克和21点等非完美信息博弈游戏。Agent-Pro的设计使其能够自我进化,适应复杂和动态的游戏环境,并通过策略层面的反思和世界模型的优化来提高自己的表现。该研究展示了AI在博弈领域的进步,同时为解决多agent现实世界问题提供了新策略。
《面向工业级推荐!“小”LLM也能做好推荐系统》。本文由蚂蚁集团AI创新研发部门NextEvo撰写,介绍了他们的论文《Can Small Language Models be Good Reasoners for Sequential Recommendation?》获得WWW 2024 (Oral)录用。文章针对大语言模型(LLM)在推荐系统应用时代价高昂的问题,提出了一种名为SLIM的基于蒸馏的大模型推荐框架。SLIM通过知识蒸馏技术,将大模型的知识和推理能力迁移到较小的模型上,从而达到用更少参数实现高效推荐的效果。论文强调SLIM在处理长尾物品和新用户推荐的优势,改进了传统基于交互数据的推荐系统偏差问题,并在保持推荐准确度和可解释性的同时降低资源消耗。
《AIOps 智能运维:有没有比专家经验更优雅的错/慢调用分析工具?》。本文介绍了阿里云应用实时监控服务 ARMS 最新推出的错/慢 Trace 分析功能。此功能不依赖专家经验,能对比分析错/慢 Trace 和正常 Trace 的每个维度,从而快速定位问题根源。针对生产环境下调用时延和错误调用的多种因素(如流量不均、单机故障等),ARMS 通过对错/慢 Trace 和正常 Trace 的对比,帮助用户发现异常的共同特征,从而定位到具体问题。这个工具提供了一种优于传统专家经验的快速、有效诊断系统问题的方法,并且附有最佳实践案例。文章最后提供了免登录的 demo 体验链接,引导用户了解和使用该功能。
《CUDA编程优化方法——Memory coalescing》。这篇文章对CUDA编程中的内存合并技术—— Memory coalescing进行了详细介绍。文章首先解释了全局内存的特点以及为何访问速度慢,并阐述了Memory coalescing的目的是通过合并内存访问操作来有效地利用带宽。通过对多维数组的存储方式及访问模式的解析,文章进一步讲解了Memory coalescing的具体实现细节,如何在多维数组访问和矩阵乘法中实现内存访问的合并。最后,文章提供了优化策略,以改进计算的内存访问模式,并提高CUDA内存传输的效率。
《扩散模型如何构建新一代决策智能体?超越自回归,同时生成长序列规划轨迹》。本篇文章介绍了扩散模型在强化学习中的多种应用场景,探讨了如何超越传统的自回归方法,同时生成长序列规划轨迹来模仿人类的决策过程。上海交通大学的团队所作的综述梳理了扩散模型在强化学习中的运用如轨迹规划、策略表征、数据合成,及其解决长序列规划误差累积、策略表达能力受限和数据稀缺等问题的巨大潜力。最终,文章对扩散模型未来的发展方向进行了展望,提出了生成式仿真环境、加入安全约束、检索增强生成及组合多种技能等多个研究方向。
《动手做一个最小RAG——TinyRAG》。本文由不要葱姜蒜指导读者如何一步步实现基于检索增强生成技术(RAG)的简化模型——TinyRAG。TinyRAG仅包含RAG核心功能,即Retrieval(检索)和Generation(生成)两个模块。文章详细介绍了RAG的基本结构,包括向量化模块、文档加载与切分模块、数据库和检索模块,以及如何根据检索内容生成回答。此外,还提供了对应的开源项目代码,助力理解语言模型与RAG的原理,并能够在实践中加以应用和拓展。
《聊一聊Transformer中的FFN》。这篇文章探讨了为什么Transformer的前馈神经网络(FFN)部分长期以来几乎没有大的改动。文章通过比较不同的激活函数,如ReLU、GeLU和Swish等,分析它们在Transformer中的应用效果和局限性。同时探讨了线性投影的必要性、参数量及其对模型容量和记忆力的影响。此外,文章还涉及了混合专家模型(Mixture-of-Experts,MoE)以提升Transformer的效率,并讨论了构建通用人工智能(AGI)所需要的结构特性,特别是放缩定律(Scaling Law)、上下文学习(In-Context Learning)、效率提升(Better Efficiency)和终生学习(Life-long learning)的重要性,最后对未来结构创新给出透彻见解。
⭐️ Go & 云原生 & Rust 相关
《More powerful Go execution traces》。Go的runtime/trace包提供了用于理解和排查Go程序的强大工具,允许对goroutine的执行进行跟踪。新版本Go大幅度降低了执行跟踪的运行时开销,从多数应用中的10-20% CPU下降到1-2%。文章介绍了如何通过将trace分割,从而使得trace可以扩展且保持低开销,还实现了飞行记录功能,使得即使在事件发生后也能从trace中获取信息。Go也提供了一个实验性的trace读取API,使程序性的跟踪分析成为可能。
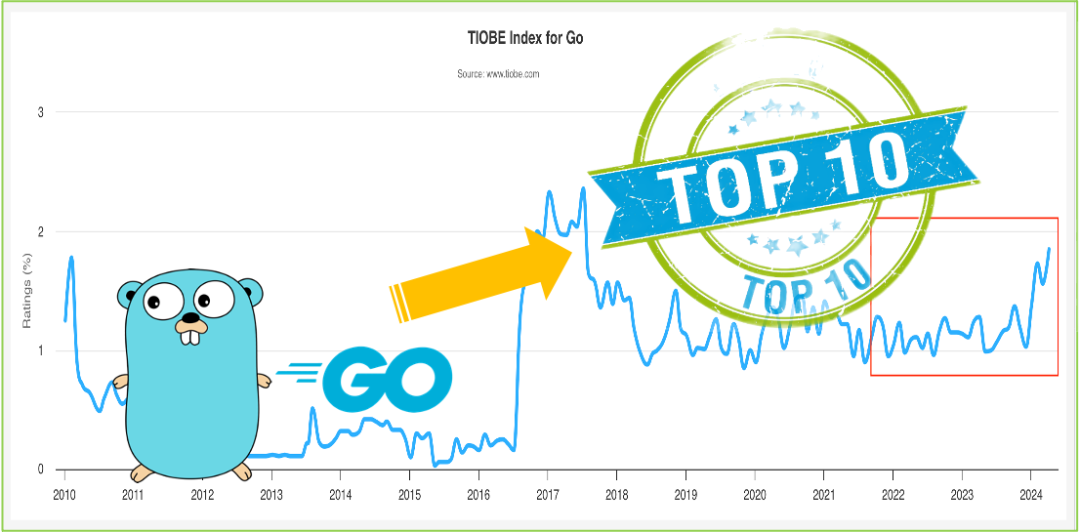
《Go 和 Google、Cloud 融合的那么深,绝非偶然》。文章作者煎鱼分析了 Go 语言与 Google 和 Cloud 融合深度的背后原因。从 2010 年 Go 在 Google 起步,到 2013 年 Google SRE 团队采用 Go 替换 Python,以及 Go 与 Kubernetes、Docker、Etcd 等云原生技术的结合,文章追溯了 Go 成功的关键节点。2016 年至 2017 年,Go 在 Google 内部增长放缓后,团队提出将 Go 应用拓展至 Cloud 领域,并最终获得了管理层的支持。加入 Cloud 部门后,Go 成为了 Cloud 的一部分,得到了更多的发展机会。文章强调,Go 与 Google 的核心开发者亲自推广及高密度的人才对 Go 发展起到了关键作用。预计未来 Go 将在云原生生态中继续崭露头角。
《Uber 出了个代码静态分析工具 NilAway,还挺实用!》。文章介绍了 Uber 开发的新静态分析工具 NilAway,它专门用于在 Go 程序编译时捕获可能导致 nil panic 的问题,以减少生产中的潜在错误。NilAway 的特点包括完全自动化、快速性能和实用性,并且在大型代码库上也表现良好。通过具体代码例子,文章展示了 NilAway 如何识别出可能导致 nil panic 的代码,并提供了安装方式和使用方法。该工具基于 go/analysis 标准开发,未来有望与 golangci-lint 等工具集成,值得关注其更新和开发进展。
《Rust: 实现比特币的交易模型》。本文详细介绍了比特币的交易模型中的UTXO(未花费交易输出)模型,并使用 Rust 语言来实现和展示其运作过程。UTXO 模型与传统的账户余额模型不同,将用户的余额分散存储在多个UTXO中。每个UTXO代表比特币网络上一笔可用于未来交易的输出。文章解释了UTXO模型的工作原理、优势以及交易处理流程,包括选择输入、生成输出、签名交易和广播交易。接着,文章提供了一个 Rust 实现的简化示例,展示了如何定义交易结构体、输入、输出以及UTXO集合,并介绍了基本的操作方法。如果你对比特币交易模型和 Rust 编程感兴趣,可以阅读该文章了解更多细节。
《深入理解 Go Modules: 高效管理你的 Golang 项目依赖》。本文详细介绍了 Go Modules 在 Golang 项目中的使用方法和原理。文章首先回顾了 Go 依赖管理的历史,从 GOPATH、Go Vendor 到 Go Module 的演进过程。然后讲解了模块、包和版本的概念,包括模块路径、包路径以及版本的格式和语义。接着,文章介绍了 Go Modules 的环境配置,包括 go env 环境变量和依赖管理文件(go.mod 和 go.sum)的作用和使用方法。最后,文章提供了一些实用技巧和常见问题的解答,帮助读者更好地理解和应用 Go Modules。如果你对 Golang 项目的依赖管理感兴趣,可以阅读该文章了解更多详情。
《Kubernetes集群节点处于Not Ready问题排查》。当Kubernetes集群中的节点显示为"Not Ready"状态时,这篇文章提供了一系列的排查步骤。首先,通过运行特定的kubectl命令来确认节点的状态并获取节点详细信息,检查可能的错误消息或者警告。接着,进入节点系统查看各种系统日志,并使用相关命令如grep、cat或tail来辅助分析。文章还建议检查kubelet服务状态和配置文件,确认系统资源是否充足,试图解决可能存在的磁盘空间和网络问题。最后,通过使用诸如ping、traceroute等诊断工具确保节点能够与主节点通信,并检查重要的网络端口是否开放。确保Kubelet能正确连接到Kubernetes API,并使用Kubernetes的诊断工具如kubectl get componentstatus检查组件状态。通过这些步骤,可以系统地排查并解决"Not Ready"的问题,保持集群健康。
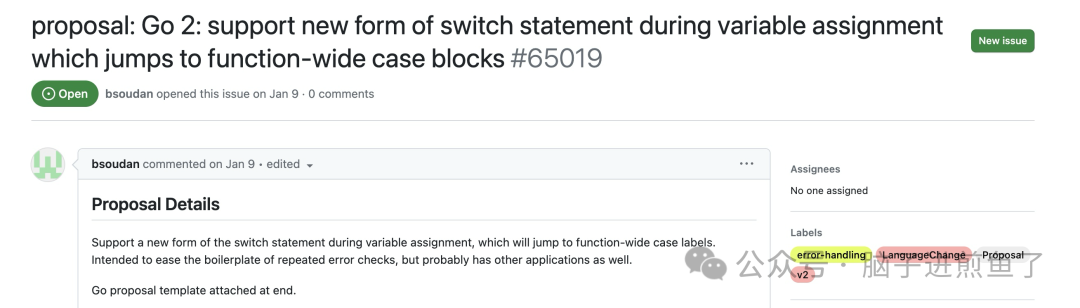
《Go 错误处理: 用 select-case 来解决这个历史难题?》。煎鱼在这篇文章中介绍了一个新的Go语言错误处理提案,这个提案尝试用select-case结构作为错误检查的替代。这个新语法允许在select关键字之后声明一个变量为“陷阱”,赋值给该变量时触发case检查,以减少传统的if err != nil检查的繁琐性。新提案保持了Go1代码的兼容性,尝试提供一个更简洁、向后兼容的错误处理方式,尽管目前社区内对此仍未达成共识。
《K8s蓝绿部署:优雅应对应用程序更新挑战》。本文详细探讨了使用Kubernetes(K8s)进行蓝绿部署的方法,以达到无缝更新应用程序并最小化宕机时间。蓝绿部署是一个运行两个相同生产环境的模式,能够在更新时切换流量,确认无误后便去除旧环境。文章指导了从创建命名空间、创建和应用部署、服务及其路由规则、执行蓝绿切换,到最后的验证和回滚过程。这一过程不仅优化了应用版本的滚动更新,也为开发者提供了快速回滚的方案,以应对可能出现的问题。
《Go 中的高速数据包处理:从 net.Dial 到 AF_XDP》。文章介绍了使用 Go 语言进行高速数据包处理的多种方法,包括 net.Dial、原始套接字、系统调用、pcap 和 AF_PACKET,直至最新的 AF_XDP 方式。作者详细对比了每种方法的性能,从简单的 net.Dial 模式演进到 AF_XDP,逐步提高数据包每秒处理数量,同时指出各方法的使用场合和限制。通过基准测试,发现使用 AF_XDP 可实现最高性能,处理速度是使用 net.Dial 方法的4倍多。这些技术探讨对于需要大量网络数据包处理的场景,如网络监控、性能评估等都是非常重要的。
《数据库不应放在容器中?- B站Kubernetes有状态服务实践(Elasticsearch/Clickhouse)》。文章探讨了在云原生时代下,有状态服务(如生产环境的数据库)是否适用于容器化并由Kubernetes进行管理的问题。以B站Elasticsearch和Clickhouse的容器化和Kubernetes编排实践为例,文章详细介绍了在容器环境中部署这些有状态服务的挑战和解决方案,包括控制器的选择、持久化存储、磁盘调度、调度器、容器网络、服务发现以及如何保证集群和数据的高可用性。作者分享了通过Operator管理有状态服务应用、使用本地盘PV提升性能、LVM技术的动态扩缩容方案以及通过macvlan进行容器间高效通信的技术细节。
《一文带您探索 Kubernetes 中的容器类型》。文章介绍了在 Kubernetes 系统中常见的四种容器类型:初始化容器(Init Container)、边车容器(Sidecar Container)、临时容器(Ephemeral Container)和多容器(Multi Container)。初始化容器用于运行 Pod 中主容器启动前的准备工作,而边车容器则与主应用容器并行运行,为其提供支持服务。临时容器主要用于故障排除,而多容器 Pods 允许并行运行多个容器,共享资源和数据。文章提供了每种容器的详细使用案例、配置方法和命令,并强调了各自的特点与应用场景。
《4 秒处理 10 亿行数据! Go 语言的 9 大代码方案,一个比一个快》。软件工程师Ben Hoyt挑战使用Go语言处理10亿行数据,并提出了9种解决方案,其中最快在4秒内完成。这些方案只使用Go标准库,包括简单但优化的map处理、并行化处理等。Ben的方案虽未最快,但展现了独立思考的价值。他的测试表明,彻底地数据处理和算法优化可显著提高性能,减少计算成本。
《Go arena 民间库来了,可以手动管理内存!》。文中作者煎鱼介绍了Go语言的一个新的第三方库ortuman/nuke,这个库允许开发者手动管理内存。文章首先回顾了Go官方对于arena手动内存管理提案的停滞现状,然后重点介绍了如何使用ortuman/nuke库进行内存管理,包括库的安装、使用案例以及如何在并发场景下保持线程安全。文章详细讲解了arena内存管理的优点,例如高效率和一次性释放,并对库的实际用法,如通过context在HTTP请求周期中管理内存,进行了展示。最后,基于性能考虑,文章还提供了并发与非并发业务场景下的基准测试结果以及性能差异。
Go 语言中如何大小端字节序?int 转 byte 是如何进行的
Go 中如何实现三元运算符?Rust 和 Python 是怎么做的
Go语言中 enum 实现方式有哪些?一定要绝对类型安全吗
Go 中如何打印结构体? 代码调试效率提升
《快看! Go 1.22 对for循环进行了两个大更新》。文章讨论了Go语言在 1.22 版本中针对for循环作出的两项主要更新:1. 每次迭代的for循环都将定义一个新的变量,不再共用同一个变量;2. 引入了对整数范围的循环迭代支持。这些更新解决了闭包在并发执行时共享变量带来的问题,同时也简化了循环结构,提高了编写对整数范围进行迭代代码的方便性。文中提供了详细的代码示例来展示新旧版本之间的差异,并说明了如何利用新特性来编写更高效的Go代码。
《从慢速到SIMD》聊Go边界检查消除》。本文讨论了Go语言中边界检查消除(BCE)的相关技巧和最佳实践。文章首先回答了为何在Go代码中优化时选择使用a[i:i+4:i+4]而不是a[i:i+4]的问题,指出前者能减少编译器工作量从而提高性能。然后,介绍了Go101提出的BCE技术详解与应用实例,以及如何使用编译命令来检测边界检查的存在。文中还全面梳理了Go BCE技术的发展历程,以及在不同场景下消除冗余边界检查的方法,包括利用循环变量、常量索引等策略来提高代码执行效率。最后,提供了多种编程技巧以及相关讨论和参考资料,针对遇到的编程问题提出解决方案。
📒 后端相关
《RocketMQ 流存储解析:面向流场景的关键特性与典型案例》。文章探讨了 RocketMQ 5.0 版本中流存储的关键特性,并针对流处理场景下的数据集成提供了详细解析。主要介绍了流存储访问模式与消息访问模式的区别,强调了流存储在大数据集成中起到异步解耦的作用。文章详细解释了 RocketMQ 5.0 版本对流存储弹性的新方案,包括静态 Topic 扩容模式和逻辑队列的引入,旨在解决传统弹性机制的限制。此外,文章还讲述了流场景对消息存储系统的高吞吐和状态维护要求,并举例了如何通过 CompactTopic 维护流状态。介绍了 Schema 概念的引入,以支持消息结构描述、提高类型安全并提升数据集成效率。最后,文章展示了流存储应用于日志采集和异构数据库同步的案例,以阐明其在实际数据架构中的作用。
《分库分表已成为过去式,使用分布式数据库才是未来》。本文讨论了随着Mysql数据库性能下降,分库分表的局限性及其所引发的问题,如性能、事务、数据迁移等,并提出使用分布式数据库作为解决方案。文章详细介绍了TiDB这款分布式数据库的架构、特性和优势,包括其金融级的高可用性、水平扩容能力、兼容性以及云原生设计。文章强调TiDB在处理大规模数据时的效率和可维护性,终结分库分表的做法,并通过性能测试展示了TiDB与MySQL在不同场景下的性能表现。最终总结,对于数据量大的应用场景,采用TiDB来适应未来数据存储的需求是一个更优的策略。
《手把手带你精简代码-京东零售后端实践》。本文分享了京东零售后端在面临代码库日渐庞大和腐化的问题时,采用的代码精简方法。文章分为背景介绍、代码精简步骤和实施方法三部分,着重介绍了使用IntelliJ IDEA自带工具和PMD插件进行静态代码检查的步骤、配置和优缺点,以及如何借助京东jacoco流水线进行动态代码检查。本文旨在降低代码维护成本、提升可理解性,并详细阐述了代码精简的实践过程和预期结果。
《跟着iLogtail学习无锁化编程》。文章探讨了在多线程情况下,如何通过无锁化编程优化软件性能。详细讲述了iLogtail在实现无锁高效日志采集时采取的策略,比如自旋锁的使用、原子操作、内存顺序、内存屏障等概念。还分析了不同类型的锁的适用场景与特点,包括互斥锁、递归互斥锁和读写锁等。此外,文章还描述了如何将大的锁细分为多个小锁,通过降低锁粒度提升并发性能,以及在iLogtail中如何通过双Buffer机制来读写分离,减少锁的争用。最终,通过无锁化编程提高了iLogtail的日志采集性能,实现了低资源消耗和高性能。
《MYSQL 是如何保证binlog 和redo log同时提交的?》。文章讨论了如何确保在MYSQL中binlog(备份和主从同步用的日志)与redo log(InnoDB引擎层的日志,用于崩溃恢复)同步提交,以及为什么这一点对于防止主从数据不一致至关重要。文中解释了事务处理中的两个关键参数:innodb_flush_log_at_trx_commit和sync_binlog,这两个值设置为1时可以确保两种日志的同步提交。该文还介绍了MYSQL的两阶段提交机制如何工作,并提出了业务开发中两阶段提交逻辑的思考,指出在有依赖关系的服务操作中,通过预锁定资源、请求成功后递减资源来保持数据的最终一致性。
《这些年背过的面试题——分布式篇》。本文从分布式系统的基础概念、发展历程及核心问题出发,详细介绍了分布式系统设计中的关键技术点。文章涵盖了负载均衡、服务的拆分与集群、分布式事务、数据一致性问题以及分区容错性等话题,并探讨了CAP理论与BASE理论在实际应用中的权衡。同时,文中还详细解读了常见的一致性算法如2PC、3PC、Paxos、Raft的机制和用例。此外,作者针对如何实现分布式Session、如何确保分布式事务的一致性等常见面试题目提供了详尽的解答,适合做为面试备考资料。
《RocketMQ为什么这么快?我从源码中扒出了10大原因!》。这篇文章详细分析了RocketMQ高性能的10个关键因素:批量发送消息降低通信次数,消息压缩减少带宽和存储压力,基于Netty的高效网络通信模型,零拷贝技术优化磁盘读写性能,顺序写提高数据写入速度,高效数据存储结构,异步机制包括异步刷盘和异步主从复制提升存储效率,批量处理减少网络通信次数和资源消耗,锁优化以及线程池隔离提升并发处理能力。作者通过深入分析源码给出了RocketMQ快速处理和拉取消息的内在原因,并深入讨论了每种技术的优势和实现。
《领导叫我接手一个新业务系统,我是这样熟悉项目的!》。本文作者小许分享了接手新业务系统的熟悉流程和实践方法。包括与产品经理交流了解业务现状,绘制用例图、ER图以明确业务与数据模型,梳理后端模型和核心流程,并运用状态机流转图和时序图深度解析复杂逻辑。最后,还提到了绘制类图以理解代码结构。文章提供了一套系统性的工具和方法,目的是帮助新成员或负责新项目的开发人员快速掌握业务逻辑,有效推进项目进度。
📒 前端相关
《Tango 低代码引擎沙箱实现解析》。本文介绍了Tango低代码引擎的沙箱实现。Tango是一个用于快速构建低代码平台的低代码设计器框架,通过对源代码进行执行和渲染前端视图,实现了低代码可视化搭建能力。借助Tango构建的低代码工具或平台可以实现源码进出的效果,并与企业内部现有的研发体系进行无缝集成。Tango的设计器引擎部分已经开源,并提供了相应的开源代码库、文档和社区讨论组。欢迎加入社区参与到Tango低代码引擎的开源建设中。更多相关文章可以在文中提供的链接中找到。
《未来只需要 2% 的程序员?》。DHH在这篇文章中提出一个激进的观点,预测未来程序员的需求可能会大幅度减少。他比较了农业从97%的人口需求降至2%的变迁,暗示软件开发也可能面临着类似缩减。尽管这个行业曾经经历招聘热潮,但现在许多程序员面临职业前景不稳定。文章讨论了人工智能的发展给程序员职业带来的压力,同时也指出职业变革的不确定性。DHH认为,未来大多数程序员可能无需手动编程,但同时指出科技行业将更加融合进社会,并提高了它的价值。他鼓励程序员接受这一变化,并享受行业的黄金时代。
《前端智能化,扣子(coze.cn)能做什么?》。这篇文章探讨了扣子(coze.cn)平台如何通过提供一个简单的交互式界面来创建聊天机器人(Chatbot)。用户通过与扣子的对话,可以快速设置一个Chatbot,如自动化微信订阅号内容发布等。文章强调了平台的易用性和界面友好性,同时指出了一些潜在缺点,包括无法解决深度问题和偶尔遇到的技术故障。另外,通过知识库和数据库的集成,可进一步提升Bot的功能。作者对扣子的机器人创建过程、优势、建议和改进进行了详细介绍,并通过实操案例展示了前端智能化机器人的搭建过程。