
📒 如何理解快速排序和归并排序
快速排序实际就是二叉树的前序遍历,归并排序实际就是二叉树的后序遍历。
快速排序的逻辑是,若要对 nums[lo..hi] 进行排序,我们先找一个分界点 p,通过交换元素使得 nums[lo..p-1] 都小于等于 nums[p],且 nums[p+1..hi] 都大于 nums[p],然后递归地去 nums[lo..p-1] 和 nums[p+1..hi] 中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码框架如下:
void sort(int[] nums, int lo, int hi) {
/****** 前序遍历位置 ******/
// 通过交换元素构建分界点 p
int p = partition(nums, lo, hi);
/************************/
sort(nums, lo, p - 1);
sort(nums, p + 1, hi);
}
先构造分界点,然后去左右子数组构造分界点,你看这不就是一个二叉树的前序遍历吗
再说说归并排序的逻辑,若要对 nums[lo..hi] 进行排序,我们先对 nums[lo..mid] 排序,再对 nums[mid+1..hi] 排序,最后把这两个有序的子数组合并,整个数组就排好序了。
归并排序的代码框架如下:
void sort(int[] nums, int lo, int hi) {
int mid = (lo + hi) / 2;
// 排序 nums[lo..mid]
sort(nums, lo, mid);
// 排序 nums[mid+1..hi]
sort(nums, mid + 1, hi);
/****** 后序位置 ******/
// 合并 nums[lo..mid] 和 nums[mid+1..hi]
merge(nums, lo, mid, hi);
/*********************/
}
先对左右子数组排序,然后合并(类似合并有序链表的逻辑),你看这是不是二叉树的后序遍历框架?另外,这不就是传说中的分治算法嘛,不过如此呀
说了这么多,旨在说明,二叉树的算法思想的运用广泛,甚至可以说,只要涉及递归,都可以抽象成二叉树的问题。
📒 Leetcode 236 二叉树最近公共祖先
lowestCommonAncestor 方法的定义:给该函数输入三个参数 root,p,q,它会返回一个节点。
- 情况 1,如果
p和q都在以root为根的树中,函数返回的即p和q的最近公共祖先节点。 - 情况 2,如果
p和q都不在以root为根的树中,则理所当然地返回null呗。 - 情况 3,如果
p和q只有一个存在于root为根的树中,函数就返回那个节点。
题目说了输入的 p 和 q 一定存在于以 root 为根的树中,但是递归过程中,以上三种情况都有可能发生,所以说这里要定义清楚,后续这些定义都会在代码中体现。
函数参数中的变量是 root,因为根据框架,lowestCommonAncestor(root) 会递归调用 root.left 和 root.right;至于 p 和 q,我们要求它俩的公共祖先,它俩肯定不会变化的。你也可以理解这是「状态转移」,每次递归在做什么?不就是在把「以root为根」转移成「以root的子节点为根」,不断缩小问题规模嘛
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// 两个 base case
// 1.如果 root 为空,直接返回 null
if (root == null) return null;
// 2.如果 root 本身就是 p 或者 q
// 例如 root 是 p 节点,如果 q 存在于以 root 为根的树中,显然 root 就是最近公共祖先
// 即使 q 不存在于以 root 为根的树中,按照情况 3 的定义,也应该返回 root 节点
if (root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 在后序位置分情况讨论
// 情况 1,如果 p 和 q 都在以 root 为根的树中
// 那么 left 和 right 一定分别是 p 和 q(从 base case 看出)
// 由于后序位置是从下往上,就好比从 p 和 q 出发往上走
// 第一次相交的节点就是这个 root,显然就是最近公共祖先
if (left != null && right != null) {
return root;
}
// 情况 2,如果 p 和 q 都不在以 root 为根的树中,直接返回 null
if (left == null && right == null) {
return null;
}
// 情况 3,如果 p 和 q 只有一个存在于 root 为根的树中,函数返回该节点
return left == null ? right : left;
}
}
在前序位置搜索节点,如果是空节点直接返回,如果搜索到
p或者q返回该节点,否则继续递归
在后序位置接收前序的返回值,如果
left和right都不为空,说明分别是p和q,当前root就是最近公共祖先,直接返回root节点。如果一个为空另一个不为空,说明找到一个节点,把这个节点向上传递,查找另一个节点,直到出现两个都不为空,此时root就是最近公共祖先,直接返回root节点
📒 如何写对二分查找
- 不要使用
else,而是把所有情况用else if写清楚 - 计算
mid时需要防止溢出,使用left + (right - left) / 2先减后加这样的写法 while循环的条件<=对应right初始值为nums.length - 1,此时终止条件是left == right + 1,例如[3, 2]- 如果
while循环的条件<,需要把right初始值改为nums.length,此时终止条件是left == right,例如[2, 2],这样会漏掉最后一个区间的元素,需要单独判断下 - 当
mid不是要找的target时,下一步应该搜索[left, mid-1]或者[mid+1, right],对应left = mid + 1或者right = mid - 1 - 二分查找时间复杂度
O(logn)
class Solution {
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
left = mid + 1; // 注意
} else if (nums[mid] > target) {
right = mid - 1; // 注意
}
}
return -1;
}
}
📒 前端三种 Content-Type
application/json:这种应该是接口请求用到最多的,可以使用 JSON.stringify() 序列化得到,实际传递的内容类似于:
{"a": "111", "b": "222"}
application/x-www-form-urlencoded:这是表单提交对应的 Content-Type,实际上就是通过 body 传递 query 参数,如使用 HTML 的表单元素,浏览器会自动进行拼接,也可通过 URLSearchParams 拼接得到,实际传递的内容类似于:
a=111&b=222
multipart/form-data:是通过 FormData 对象构造出来的表单格式,通常用于文件上传,实际传递的报文内容类似于:
POST /test.html HTTP/1.1
Host: example.org
Content-Type: multipart/form-data;boundary="boundary"
--boundary
Content-Disposition: form-data; name="field1"
value1
--boundary
Content-Disposition: form-data; name="field2"; filename="example.txt"
value2
--boundary--
顺便提一下,文件下载对应的 Content-Type 是
application/octet-stream
📒 如何理解 Node.js 模块
一个模块实际上可以看做一个 once 函数,头部的 require 命令可以看做入参,module.exports 可以看做返回值。
当首次加载一个模块的时候,就会运行这个模块代码,可以看做是调用一个函数,执行结束后得到导出的内容并被缓存,可以看做函数返回一个值。当再次加载这个模块,不再执行这个模块代码,而是直接从缓存中取值。
在一个函数中,我们知道可以使用 return 语句提前结束运行,那么在模块中如何实现呢,答案是使用 process.exit(1):
const fs = require("node:fs");
const path = require("node:path");
const webpack = require("webpack");
const workDir = process.cwd();
const envFilePath = path.resolve(workDir, "./.env.local");
const hasEnvFile = fs.existsSync(envFilePath);
if (!hasEnvFile) {
process.exit(1);
}
module.exports = {
mode: "development",
entry: './src/index.js',
output: {
path: path.resolve(__dirname, './dist'),
filename: '[chunkhash].bundle.js',
clean: true
},
}
这里注意下,
fs.exists()方法已经废弃了,但是fs.existsSync()仍然可用。此外还可使用fs.stat()或者fs.access()检查文件是否存在
📒 在 TIME_WAIT 状态的 TCP 连接,收到 SYN 后会发生什么?
📒 一键部署 K8S 环境,10分钟玩转,这款开源神器实在太香了!
📒 charles 如何连接手机抓包
- 确保手机和电脑连接的是同一个网络
- 首先打开 charles,会启动一个服务,查看端口:proxy -> proxy setting
- 勾选 Enable transparent HTTP proxying
- 查看本机 IP
- 在手机上设置 http 代理服务器,输入 IP 和端口
- 此时 charles 会弹出提示,有新的连接,点击 allow
📒 前端项目的 .env 文件是如何生效的,一句话总结
通过 dotenv 这个包解析 .env 文件,加载到 process.ENV 里面,这时候可以通过 process.ENV.xxx 访问到环境变量,适用于 Node.js 项目,但是由于浏览器环境访问不到 process 对象,所以对于前端项目,还需要使用 Webpack 的 DefinePlugin 在打包构建阶段将变量替换为对应的值。
📒 如何防止用户篡改 url 参数
http://localhost:8080/codepc/live?codeTime=1646038261531&liveId=5e24dd3cf03a&sign=e8fe282676f584ceab7e35f84cbc52ff&keyFrom=youdao
前端的直播链接带有 codeTime 和 liveId,如何防止用户篡改。只需要后端在返回 codeTime 和 liveId 的时候,同时计算一个签名 sign 返回给前端,前端提交给后端的时候,同时传递三个参数,后端计算一个新的签名,与前端传过来的 sign 进行比对,如果一样就说明没有篡改。
但是计算签名用的 md5 是一个公开的算法,假如有人篡改了 codeTime 和 liveId ,只要他使用 md5 计算一个新的签名 sign ,这样传给后端校验必然可以通过。这就需要后端签名的时候拼接一个加密串进去,验签的时候也用这个加密串。这样由于别人不知道加密串,即便生成新的签名,后端校验也不会通过。
📒 Screenshot: 不依赖浏览器原生能力的截屏库
该库基于 MediaDevice API 来提供了易于截屏的抽象。如果你有兴趣可以来看看 GitHub 仓库
📒 enum-xyz:使用 Proxy 实现 JavaScript 中的枚举
一个 js-weekly 的读者,分享的有趣实现思路。源码很短,推荐看一下
📒 如何使用代理模式优化代码
开发环境下打印日志:
const dev = process.env.NODE_ENV === 'development';
const createDevFn = (cb) => {
return (...args) => dev && cb(...args);
};
const log = createDevFn(console.log);
log("23333"); // "2333"
异常捕获:
class ExceptionsZone {
static handle(exception) {
console.log('Error:',exception.message, exception.stack);
}
static run(callback) {
try {
callback();
} catch (e) {
this.handle(e);
}
}
}
function createExceptionZone(target) {
return (...args) => {
let result;
ExceptionsZone.run(() => {
result = target(...args);
});
return result;
};
}
const request = () => new Promise((resolve) => setTimeout(resolve, 2000));
const requestWithHandler = createExceptionZone(request);
requestWithHandler().then(res => console.log("请求结果:", res));
📒 VuePress 博客优化之开启 Algolia 全文搜索
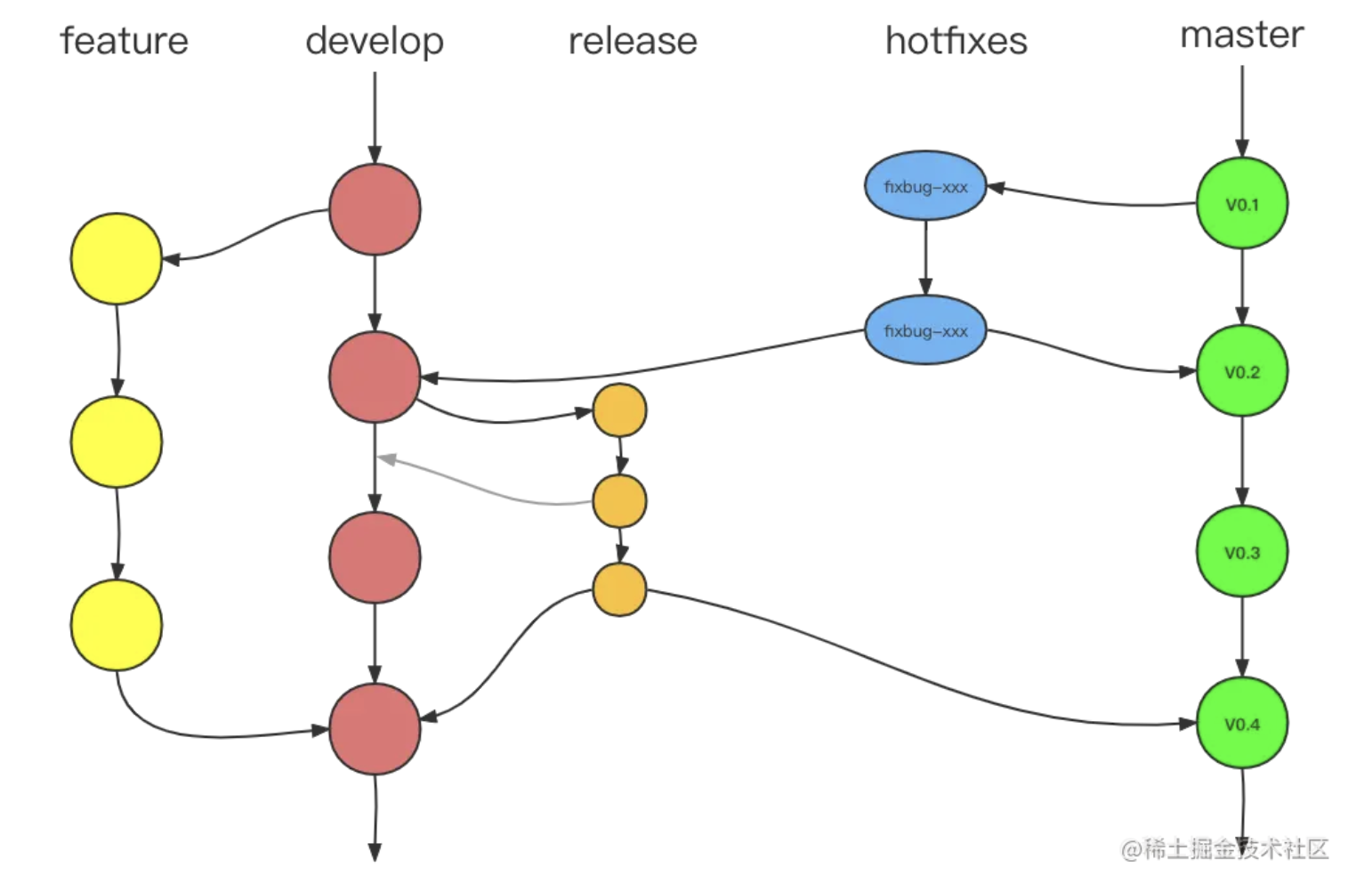
📒 Git 分支操作流程
在 Git Flow 中,有两个长期存在且不会被删除的分支:master 和 develop
master主要用于对外发布稳定的新版本,该分支时常保持着软件可以正常运行的状态,不允许开发者直接对 master 分支的代码进行修改和提交。当需要发布新版本时,将会与master分支进行合并,发布时将会附加版本编号的 Git 标签develop则用来存放我们最新开发的代码,这个分支是我们开发过程中代码中心分支,这个分支也不允许开发者直接进行修改和提交。程序员要以develop分支为起点新建feature分支,在feature分支中进行新功能的开发或者代码的修正
注意
develop合并的时候,不要使用fast-farward merge,建议加上--no-ff参数,这样在master上就会有合并记录
除了这两个永久分支,还有三个临时分支:feature branches、hotfixes 以及 release branches
feature branches是特性分支,也叫功能分支。当你需要开发一个新的功能的时候,可以新建一个feature-xxx的分支,在里边开发新功能,开发完成后,将之并入develop分支中hotfixes就是用来修复 BUG 的。当我们的项目上线后,发现有 BUG 需要修复,那么就从master上拉一个名为fixbug-xxx的分支,然后进行 BUG 修复,修复完成后,再将代码合并到master和develop两个分支中,然后删除hotfix分支release branches是发版的时候拉的分支。当我们所有的功能做完之后,准备要将代码合并到master的时候,从develop上拉一个release-xxx分支出来,这个分支一般处理发版前的一些提交以及客户体验之后小 BUG 的修复(BUG 修复后也可以将之合并进develop),不要在这个里边去开发功能,在预发布结束后,将该分支合并进develop以及master,然后删除release
📒 百行代码带你实现通过872条Promise/A+用例的Promise
📒 颜值爆表!Redis 官方可视化工具来啦,功能真心强大!
📒 程序员开源月刊《HelloGitHub》第 71 期
C 项目
chibicc:迷你 C 编译器。虽然它只是一个玩具级的编译器,但是实现了大多数 C11 特性,而且能够成功编译几十万行的 C 语言项目,其中包括 Git、SQLite 等知名项目。而且它项目结构清晰、每次提交都是精心设计、代码容易理解,对编译器感兴趣的同学可以从第一个提交开始学习
Go 项目
nali:离线查询 IP 地理信息和 CDN 服务提供商的命令行工具
revive:快速且易扩展的 Go 代码检查工具。它比 golint 更快、更灵活,深受广大 Go 开发者的喜爱
go-chart:Go 原生图表库。支持折线图、柱状图、饼图等
Java 项目
thingsboard:完全开源的物联网 IoT 平台。它使用行业的标准物联网协议 MQTT、CoAP 和 HTTP 连接设备,支持数据收集、处理、可视化和设备管理等功能。通过该项目可快速实现物联网平台搭建,从而成为众多大型企业的首选,行业覆盖电信、智慧城市、环境监测等
from-java-to-kotlin:展示 Java 和 Kotlin 语法上差别的项目。让有 Java 基础的程序员可以快速上手 Kotlin