📒 rollup 配置优化方案
// 打包引用主入口文件
const appIndex = ["ESM", "CJS"].map(format => ({
input: path.resolve(__dirname, 'index.js'),
format,
external: ["./pyodide.worker.js"],
output: {
file: path.resolve(__dirname, 'dist/client', 'env.mjs'),
sourcemap: true
}
}));
// 打包 worker 文件
// 目的是让 rollup 也处理下这个文件
const worker = [
{
input: path.resolve(__dirname, 'pyodide.worker.js'),
output: {
file: path.resolve(__dirname, 'dist/client', 'pyodide.worker.js'),
sourcemap: true
}
}
]
export default [...appIndex, ...worker];
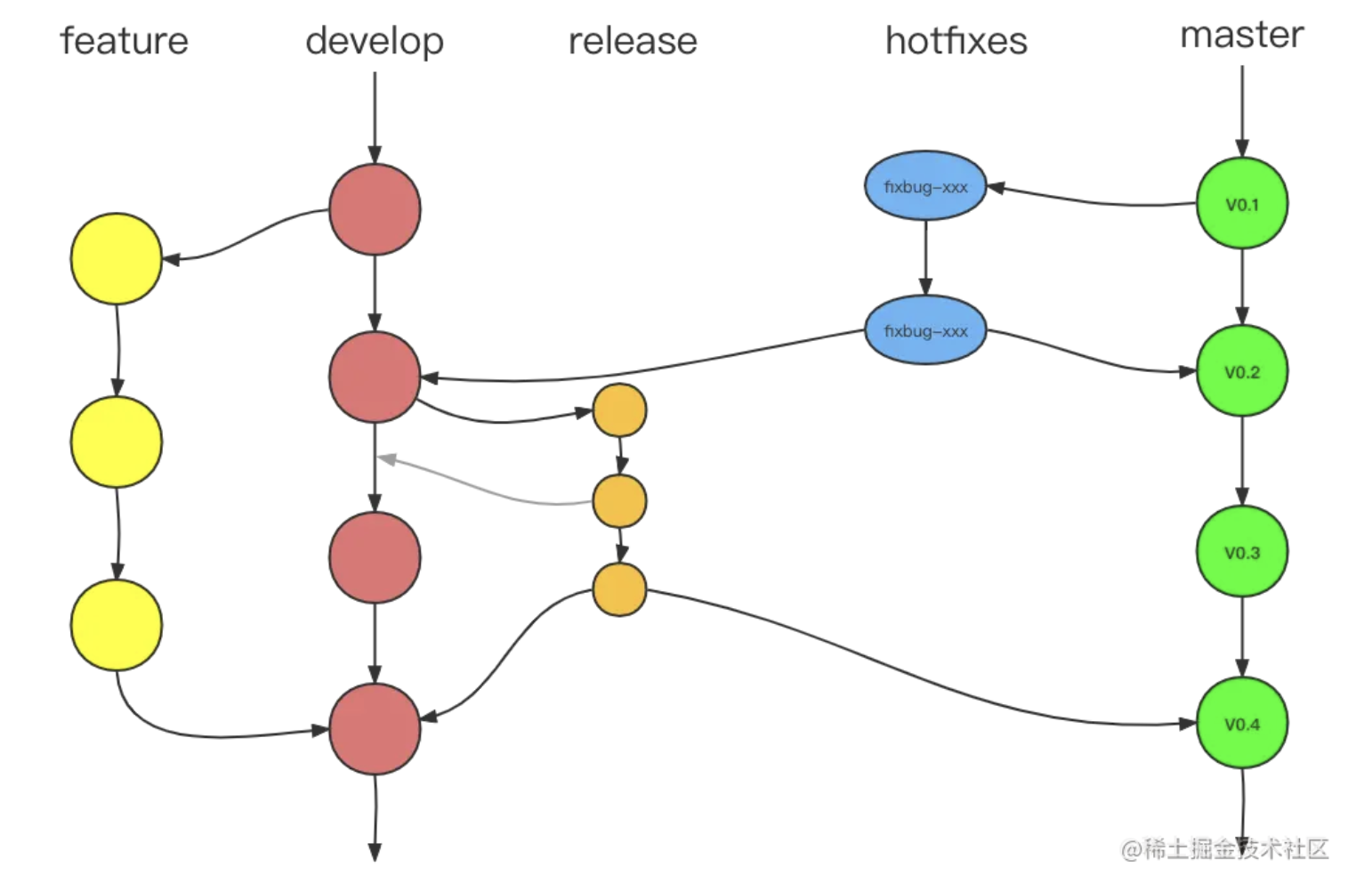
📒 Git merge 三种策略
git merge:默认使用 fast-forward 方式,git 直接把 HEAD 指针指向合并分支的头,完成合并。属于“快进方式”,不过这种情况如果删除分支,则会丢失分支信息。因为在这个过程中没有创建 commitgit merge --no-ff:强行关闭 fast-forward 方式,可以保存之前的分支历史。能够更好的查看 merge 历史,以及 branch 状态git merge --squash:用来把一些不必要 commit 进行压缩,比如说,你的 feature 在开发的时候写的 commit 很乱,那么我们合并的时候不希望把这些历史 commit 带过来,于是使用--squash进行合并,需要进行一次额外的 commit 来“总结”一下,完成最终的合并
📒 Git 如何变基拉取代码
在本地 commit 之后,下一步一般会执行 git pull 合并远程分支代码。我们知道 git pull 相当于 git fetch && git merge,通过 merge 方式合并代码,缺点就是会导致时间线比较混乱,出现大量没用的 commit 记录,给 Code Review 带来不便。另一种方式是变基拉取:
$ git pull --rebase
在变基操作的时候,我们不去合并别人的代码,而是直接把我们原先的基础变掉,变成以别人修改过后的新代码为基础,把我们的修改在这个新的基础之上重新进行。变基的好处之一是可以使我们的时间线变得非常干净。
变基操作的时候,会创建一个临时的 rebasing branch,如有冲突,合并完冲突的文件,添加到暂存区后,执行:
$ git rebase --continue
此时会进入 commit message 编辑界面,输入 :q 就会提交 commit,后续只要推送远程仓库即可。
如果不想继续变基操作,执行:
$ git rebase --abort
📒 Git 操作之 git push -f
在开发一个项目的时候,本人将自己的 feature 分支合并到公共 test 分支,并且在测试环境部署成功。
几天后再去看的时候,发现测试环境提交的代码都不见了,本人在 test 分支的提交记录也都没了,只有另外一个同事留下的提交记录。最后重新将 feature 分支合到 test,再次部署到测试环境。
这个事情虽然影响不是很大,毕竟只是部署测试环境的分支,没有影响到 feature 分支,但是后来一直在想,究竟什么操作可以覆盖别人的提交记录。想来想去,应该只有下面几种情况:
git reset:回退版本,实际上就是向后移动HEAD指针,该操作不会产生 commit 记录git revert:撤销某次操作,用一次新的 commit 来回滚之前的 commit,HEAD继续前进,该操作之前和之后的 commit 和 history 都会保留git push -f:将自己本地的代码强制推送到远程仓库。当使用git push推送报错时,除了耐心解决冲突再提交之外,还可以使用这个命令强制推送,但通常会造成严重后果,例如覆盖别人的提交记录
由于开发一般都在自己的 feature 分支上,只有在需要测试的时候才会合并 test 分支,因此使用 git reset 可能性不大。git revert 更不可能,不仅不会修改 history,同时还会创建一条新的 commit 记录。因此可能性最大的就是 git push -f 了。
一般我们推送代码之前都会习惯性执行 git pull,就算不执行 git pull,直接推送,只要有人在你之前推送过也会报错:
$ git push -u origin main
error: failed to push some refs to 'https://github.com/Jiacheng787/git-operate-demo.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
在这种情况下,常规做法是执行 git pull 更新本地提交记录,如有冲突则解决冲突,然后再次推送。另一种做法就是强制推送:
$ git push -f origin main
可以看到就算没有事先 git pull 也不会报错,但是这样会导致远程仓库的提交记录被覆盖,远程仓库的提交记录变成了你本地的记录,你上次同步代码之后别人的提交记录都丢失了。
如何删除所有 commit 记录
初始化一个仓库:
$ git init
本地提交:
$ git add .
$ git commit -m "Initial commit"
下一步强制推送到远程仓库即可:
$ git branch -m main
$ git remote add origin <REPO_TARGET>
$ git push -f origin main
📒 Docker 容器如何实现持久化
Docker 容器本身是无状态的,无法持久化存储,在 Docker 容器中构建前端项目,如何缓存 node_modules 从而提升构建效率?可以给 Docker 容器挂载外部数据卷,映射到本地文件系统,就可以实现持久化存储。
📒 GitHub 最受欢迎的Top 20 JavaScript 项目
- yargs: 通过使用 Node.js 构建功能全面的命令行应用,它能轻松配置命令,解析多个参数,并设置快捷方式等,还能自动生成帮助菜单
- Ajv: 一个适用于 Node.js 和浏览器的最快 JSON 验证器
- yallist: 一个双向链表的实现
- rimraf: Node.js 的 rm -rf 实用程序。以包的形式包装rm -rf命令,用来删除文件和文件夹,不管文件夹是否为空,都可以删除
GitHub 最受欢迎的Top 20 JavaScript 项目
📒 如何提升 GitHub Page 访问速度
打包构建
使用 GitHub Action 作为 CI 环境,使用 Docker 进行构建,充分利用缓存,如 package.json 没变就不重复装包。
部署
打包之后将静态资源上传至阿里云 OSS(需要配置 Webpack 的 output.publicPath),提升页面加载速度。
HTML 页面暂时可以不上传,使用 GitHub Page 托管,这样访问速度可以保证,但是不能解决 GitHub Page 偶尔会挂的问题。还是要将 HTML 页面上传(Cache-Control:no-cache),此时整个网站完全托管在阿里云 OSS 上面,需要域名备案。
如果页面需要后端服务,也可以不用服务器,直接使用 云数据库 + 云存储 + Serverless 云函数,免去运维成本。
📒 Golang 算法
📒 Golang 项目参考
📒 函数式编程(FP)
lodash 中的 FP
在lodash的官网上,我们很容易找到一个 function program guide 。在 lodash / fp 模块中提供了实用的对函数式编程友好的方法。里面的方式有以下的特性:
- 不可变
- 已柯里化(auto-curried)
- 迭代前置(iteratee-first)
- 数据后置(data-last)
假如需要将字符串进行如下转换,该如何实现呢?
例如:
CAN YOU FEEL MY WORLD->can-you-feel-my-world
import _ from 'lodash';
const str = "CAN YOU FEEL MY WORLD";
const split = _.curry((sep, str) => _.split(str, sep));
const join = _.curry((sep, arr) => _.join(arr, sep));
const map = _.curry((fn, arr) => _.map(arr, fn));
const f = _.flow(split(' '), map(_.toLower), join('-'));
f(str); // 'can-you-feel-my-world'
我们在使用 lodash 时,做能很多额外的转化动作,那我们试试 fp 模块吧。
import fp from 'lodash/fp';
const str = "CAN YOU FEEL MY WORLD";
const f = fp.flow(fp.split(' '), fp.map(fp.toLower), fp.join('-'));
f(str); // 'can-you-feel-my-world'
这种编程方式我们称之为 PointFree,它有 3 个特点:
- 不需要指明处理的数据
- 只需要合成运算过程
- 需要定义一些辅助的基本运算函数
注意:FP 中的 map 方法和 lodash 中的 map 方法参数的个数是不同的,FP 中的 map 方法回调函数只接受一个参数
📒 手写 Webpack
手写webpack核心原理,再也不怕面试官问我webpack原理
📒 Golang 指针几点注意
- Golang 中赋值操作、函数参数、函数返回值都是 copy
- 基本类型、slice、map 直接传递就行,对于 struct、array 需要特别注意,建议一律传递指针类型
📒 Dum:Rust 编写的 npm 脚本运行器
延续了使用不是 JavaScript 来构建 JavaScript 工具的趋势。这个奇怪的名字 “Dum”,旨在取代 npm run 和 npx 来减少任务启动时间的毫秒数。
📒 Node 之道:关于设计、架构与最佳实践
📒 Hooks 的 ”危害性“
作者声称“每周都能找到十几个与 hooks 相关的问题”,并利用这段经历给出了一些例子和解决方法,以避免“API 的不足之处”。
📒 Dockerfile 配置
# 两段式构建
# 第一段构建源码镜像
ARG PROJECT_DIR=/project
ARG BB_ENV=prod
FROM harbor.hiktest.com/public/vue:2.5-node10 as src
ARG PROJECT_DIR
ARG BB_ENV
COPY . ${PROJECT_DIR}/
WORKDIR ${PROJECT_DIR}/
RUN npm install && npm run build:${BB_ENV}
# 第二段从源码镜像中拷贝出编译的dist,做成目标镜像
FROM harbor.hiktest.com/hikvision/nginx:1.12
ARG PROJECT_DIR
ENV LANG=en_US.UTF-8 LANGUAGE=en_US:en LC_ALL=en_US.UTF-8 TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
COPY --from=src ${PROJECT_DIR}/dist /usr/share/nginx/html/
COPY ./nginx.conf /etc/nginx/nginx.conf
COPY ./default.conf /etc/nginx/conf.d/default.conf